本部分将把”阅读打卡”小程序的数据存储到数据库中去.
涉及两个主要内容: (1) 数据库设计 (2) 数据库交互
19. 数据库设计
数据库就是存储数据的地方, 这谁都懂… 很多同学甚至还学习过数据库理论, 然而这些理论到底如何应用到实践中呢? 这往往是”科班”出身的新手最大的问题.
具体来说, 若要求你为本教程的 “阅读打卡” 小程序设计数据, 该怎么做呢? 本节我们就来讨论这个问题…
一般而言我们可以把数据库设计的实践过程分作 3 步:
(1) 分析我们的程序涉及了哪些”坨”数据
(2) 分析这些一坨坨数据之间存在什么样的关系
(3) 创建数据库表, 建立表之间的关系
下面分别解释…
19.1 数据分坨
首先, 要明白数据会”自然”形成一坨一坨的状态. 其次, 一坨坨的数据之间通常是有关联的.
呵呵~ 越看越不明白我在说什么了… 那我们就结合”阅读打卡”小程序来聊一聊…
打开你的小程序主界面, 找出那些**”活”**的数据项, 它们正是我们需要使用数据库来存储的数据.
比如: 关注数, 粉丝数, 日记数, 日记的标题, 内容, 封面图片, 音频信息…
然后, 给这些数据项分一下类…
比如: 关注数, 粉丝数, 日记数 这些都是跟用户相关的信息, 于是, 我们可以认为他们是一坨数据.
而日记标题, 内容, 封面图片等信息都是日记的信息, 于是, 可以认为这又是一坨数据.
然后, 把这些坨坨的数据归类表达出来…
比如: user_info ( favCnt, fansCnt, diaryCnt … ) , diary ( title, content, cover … )
于是, 我们就可以得到用计算机的思维表达的两坨数据的结构, 说白了, 就是数据库基本表的大致结构. 哈哈, 这个动作似乎我们已经做过了, 不信的话, 你往前翻翻, 教程中多次提到的小程序数据模型不就是这个造型吗?
只要你不是太有”扛精”精神, 那么上面把数据分成”用户信息”和”日记信息”两坨, 应该是一个很”自然”的想法. 所以… 跟着感觉走就行了… 别成天跟自己过不去.
当然, “扛精”们会说, 那日记也是用户发表的呀, 日记标题, 内容等信息跟用户信息放在一起也很合理啊, 不信你看小程序主界面上, 每一条日记列表项不止有日志标题, 内容, 还有日志作者, 而作者姓名不就是用户信息吗?
呵呵, 好像有点道理哦 ~ 不过, 我只想说, 你高兴就好! 一会再来收拾你!
理论上, 可以把一个项目中涉及的所有数据都算作是”一坨”, 即: 项目相关的所有数据都存储在一个表中. 只要满足”表中的每一个字段都是不可拆分的”, 那么就已经满足了数据库设计的最低要求: 1范式. 但是这样做会带来很多问题, 比如: 数据冗余, 插入/删除/更新异常… 所以, 根据数据库设计理论, 需要对数据进行拆分, 即”模式分解”, 我们这里叫”分坨”. 而根据模式分解后数据库达到的规范化程度从低到高可分为: 1范式(1NF) → 2范式(2NF) → 3范式(3NF) → BC范式(BCNF) → 4范式(4NF) → 5范式(5NF) .
模式分解的过程即是逐步提高数据库设计规范化程度的过程, 是把上面提到的数据冗余以及各种异常问题变得越来越少的过程. 当然, 也是把数据拆得越来越散的过程, 这样在维持数据一致性/完整性方面可能会带来更大的性能消耗, 多表连接查询时也同样会有更多的性能消耗. 所以, 实践中需要在规范化程度, 空间复杂度 和 时间复杂度三者之间寻找”平衡”.
本文的重点并非讲解数据库理论知识, 因为…… 我猜你看不懂, 哈哈~ 即使看懂了, 实践还是不知如何下手…
所以, 这里只想教你最直观, 易实操的方法. 总之, 跟着来就是了~
19.2 坨坨间的联系
分清数据大致有几坨后 ( user_info, diary ) , 接着梳理这一坨坨数据之间存在什么样的联系.
这就是刚才 “扛精” 们纠结的问题, 日记是用户发表的, 所以用户和日记是有关系滴.
更进一步说, 用户和日记之间的这种关系是1对多关系. 因为1个用户(作者)可以发表 n 篇日记( 1 → n ), 相反1篇日记的作者(用户)只有1个( 1 → 1 )
这个绕口令是不是似曾相识? 呵呵, 教数据库原理的老师经常这么念…
不过, 我想提醒一点, 我们说1对多(1:n)关系是站在更高的角度”俯视”用户和日记的关系得到的结论. 如果你是站在”平视”的角度, 即从1个用户(作者)的角度看日记, 是1→ n, 而站在1篇日记的角度看用户(作者)则是 1 → 1
19.3 数据表设计
OK ~ 现在就可以开始在数据库中创建表了…
为了统一认识, 明确一下用户表和日记表中具体的字段:
用户表 ( user_info )
| 字段名 | 数据类型 | 备注 |
|---|---|---|
| id | char(36) | 主键 |
| wxId | char(36) | 微信ID |
| nickName | char(64) | 用户昵称 |
| favCnt | int | 关注数 |
| fansCnt | int | 粉丝数 |
| diaryCnt | int | 日记数 |
wxId: 将来用于存放用户的微信ID, 此处先预留.
日记表 ( diary )
| 字段名 | 数据类型 | 备注 |
|---|---|---|
| id | char(36) | 主键 |
| title | varchar(64) | 日记标题 |
| publishTime | datetime | 发表时间 |
| cover | varchar(128) | 封面图片路径 |
| content | text | 日记内容 |
| audioPath | varchar(128) | 音频文件存储路径 |
| audioDuration | int | 音频时长 |
| readCnt | int | 阅读数 |
| praiseCnt | int | 收获的点赞数 |
注意, diary 表中没有作者 (author)字段
上面 2 个表都手动地添加了 id 字段作为主键. 所谓”手动”的意思是, 上一节的分析过程中我们并没有提到id字段, 这里纯粹是根据”程序员的专业素养”加上去的. 至于什么是**主键(Primary key)**本文不作赘述.
学习数据库知识时经常会提到一个”经典”的例子: 学生信息表的主键是学号, 而课号可作为课程信息表的主键…. 哎, 相信我, 别用什么学号作主键… 最好自己手动添加一个 id. 原因嘛…… 要不要我跟你讲讲身份证号码都会重复的故事…
相信大多数同学根据上面的表结构, 在 MySQL (或其它数据库管理系统) 中创建两个对应的表并没有什么大问题…
但是, 细看之下你会发现, 上面 2 个表只表达出了 19.1 节分析的结果. 而 19.2 节中所述的用户表与日记表之间的1:n关系并没有表达出来.
不表达这个关系可以吗? 答案是 NO ! 因为, 如果不表达上述 1:n 关系, 你就不知道某篇日记是谁发表的, 相反, 也你不能回答某个用户发表了哪些日记这个问题…
所以, 我们还非得在上面的表结构中表达出这个关系… 可以这样做:
对于 1:n 关系, 在 n 的那边添加外键字段, 对应 1 那边表的主键
嘿嘿, 看不懂, 是吧 ~ 别急, 下面解释完你再回来把上面这句话记录下来.
对于上面的两个表, 所谓的 n 那边指的是 “日记表”, 而 1 那边则是 “用户表”.
所以, 你需要在日记表(diary)中添加一个字段(userId), 而这个字段即是所谓的外键, 它将关联用户表(user_info)的主键字段(userId).
即日记表应变成这个样子: 日记表 ( diary )
| 字段名 | 数据类型 | 备注 |
|---|---|---|
| id | char(36) | 主键 |
| userId | char(36) | 用户(作者) ID, 外键 |
| … | … | … |
( 为了省纸, 上表中原有的字段就没有重复列出来了, 自行脑补… )
直观一点, 看下图:
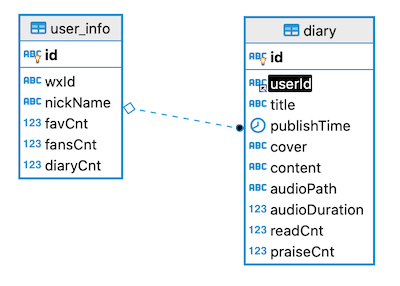
图中加粗的那两个 id 字段分别是两个表的主键, 而 diary 中黑底白字的 userId 即是外键. 而中间的虚线则表达了两个表之间的外键关联关系: user_info.id ↔ diary.userId
下图是填充了实际数据后的样子:

图中红色的箭头标注了所谓的外键关联, 看出来了吧, 箭头两端 的 user_info.id 和 diary.userId 值是相同的.
这样的话, 如果我问你, Bailey (u1) 发表了哪些日记, 你就可以在 diary 表中找出 userId 字段值是 u1 的那些日记记录. 相反, 如果问你白雪公主这篇日记 (d3) 是由谁发表的? 那么你就可以在 user_info 表中找到外键值(u3)对应的记录, 即: 小宝贝.
这回, 明白外键是干什么用的了吧 ~
再写条 SQL 语句说明一下, 这就是查 Bailey 发表的所有日记信息:
1 | select diary.* |
嘿嘿, 发现 第 4 行的小秘密了吗? 它是外键字段上的等值条件.
在数据库理论里, 把两个表”拼起来”的这种查询称作连接查询.
连接查询时一定会需要在 where子句中添加”连接条件” (第4行的条件), 否则查询结果将是传说中的笛卡积(Cartesian product). 也就是说, 第4行的”连接条件” 把那些”非法(不正确)”的数据从笛卡积中筛除.
特别地, 若是外键字段上的等值连接查询 ( 以外键字段值相等(匹配)作为连接条件), 则称作自然连接查询. ( 真的好自然! )
类似地, 再看 2 个常用的查询:
1 | -- 查询所有"发表过日记"的用户以及他们所发表的所有日记信息. 相当于 select * from user_info, diary where user_info.id = diary.userId |
看完前面 3 个 select 语句, 你会发现, 外键字段经常出现在连接查询的”条件”部分(where子句). 所以, 实践中常会在外键字段上创建索引(index) 以提高查询效率.
很想动手试试吧~ 请看下节…
19.4 创建数据表
本教程使用 MySQL 数据库管理系统 (DBMS), 同时使用 DBeaver 作为数据库管理工具. 关于这两个东东的安装使用方法请自行百度.
为免去你手动建库的过程, 这里附上建库的 SQL, 请自行复制享用…
1 | -- 创建数据库,名为daily_reading |
解释几个地方:
- 第 35 行, 在外键字段 userId 上创建索引.
- 第 36 行, 建立 diary 与 user_info 表之间的外键关系
好了, 现在数据库也建好了, 里面还有几条测试数据. 我们来练习一下, 为后续内容做准备…
当然, 如果你瞄一眼觉得这完全是在侮辱你的智商, 那完全可以跳过…
1 | -- 查询 id='u1' 的用户信息 |
上面的部分代码后文中会使用到, 如果后面遇到看不懂的 SQL 语句, 可以回来这里瞧瞧…
19.5 1:1, 1:n 与 m:n (选修)
写到上一节, 原本已完全够应付我们的”阅读打卡”小程序开发的需求了.
但是, 本着学雷锋, 做好事的精神, 我们加一节选修课, 聊一聊如何在实际的数据库表设计中体现出数据库理论中的那些所谓的1:1, 1:n, n:m 关系.
- 1 对 1 ( 1 : 1 )
这很简单, 比如需要存储”钥匙”和”锁”的信息, 呵呵~
一把钥匙开一把锁, 它们就是天生的一对一关系. 你可以把钥匙和锁的信息都放在一个表中即可.
当然, 如果钥匙和锁的信息很复杂(字段很多), 也可以考虑把它们拆开, 分别放在两个表中, 此时, 在任意一个表中添加外键去关联对方的主键即可. 如图:
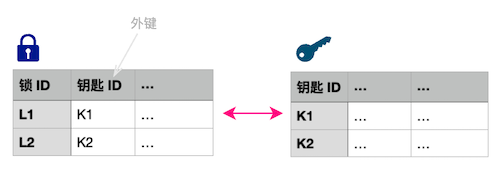
试试看, 你是否可以轻松回答 2 个问题: 钥匙 K1 可以开哪把锁? 锁 L1 的钥匙是哪一把?
然后, 自己尝试写一下回答上述问题的 select 语句…
- 1 对多 ( 1 : n )
在 19.3 节, 我们已经讨论了 1 对多关系(用户与日记)的表达方式, 此处就不再赘述了.
只重复一下结论: 对于 1:n 关系, 在 n 的那边添加外键字段, 对应 1 那边表的主键.
- 多对多 ( n : m )
有了表达1对多关系的基础, 有些时候, 我们会”莫名其妙”地就表达出了多对多关系.
举个例子: 如果我们的小程序需要提供”评论”功能, 即: 记录用户对某篇日记的评论.
很自然地, 你会想到应该需要增加一个评论信息表(comment), 表中的每一条数据大概会记录这样一些信息: 谁评论的? 针对哪条日记的评论? 评论内容是什么?
翻译成数据库表结构设计, 大概就是至少需要评论人ID (谁评论), 日记ID (针对哪条日记的评论) 和 评论内容 三个字段. 就像下图的样子:
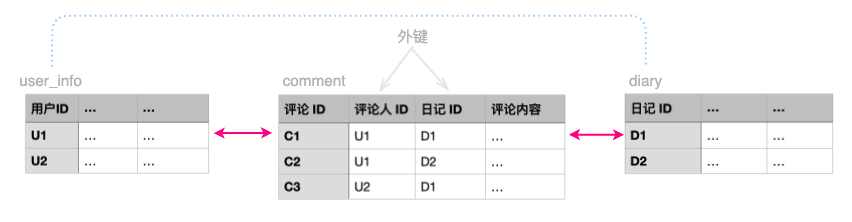
呵呵, 可能你自己都没意识到, 你在 comment 表中放了两个外键字段: 评论人ID和日记ID, 而它们分别关联用户表和日记表.
嘿嘿~ 就是这么自然 ~ 就是这么莫名其妙, 你竟然表达出了评论人和日记之间的”多对多”关系 ( 图中蓝色虚线, 想一想, 一个用户可以评论多篇日记, 一篇日记可以被多个用户评论, 确实是多对多关系, 我没骗你, 呵呵~ )
试试看, 你是否可以轻松回答 2 个问题: 用户 U1 评论了哪些日记? 日记 D1 被哪些人评论过?
当然, 有些时候, 你明明知道两个表之间是多对多关系, 但偏偏脑子短路…
比如: 假设我们的程序中还支持创建阅读组(reading_group), 即: 一个用户可以参与到不同的阅读组中去, 当然一个阅读组中可能会有很多用户.
是不是已经感觉出来了: 我们需要增加记录阅读组信息的表(reading_group), 而用户和阅读组之间的关系是一个多对多关系.
增加表容易, 但用户和阅读组之间的多对多关系怎么表达?
在用户表中加阅读组ID? 在阅读组表中加用户ID? 比划一下, 是不是感觉有点蒙了~
其实, 上面”评论”的例子已经给了我们暗示… 借助”评论表”, 我们表达出了评论人和日记之间的多对多关系, 只是上例中的评论表似乎很自然地就自己冒出来了…
而在这里, 多对多关系的两端都有了(用户和阅读组), 却唯独缺了中间的”桥”, 因此, 这里我们需要主动去构建这第 3 个表 ( 下图中的 user_x_group )
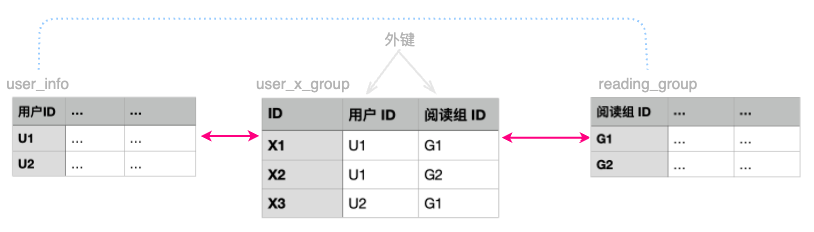
试试看, 你是否可以轻松回答 2 个问题: 用户 U1 加入了哪几个阅读组? 阅读组 G1 里都有些什么人?
好了~ 现在是不是可以得到一个结论了:
- 多对多关系 ( n:m ) 需要引入第 3 个表, 在这个表中有 2 个外键字段, 分别 “拉” 着两头的 n 和 m
- 站在这第 3 个表的位置 ( 如: comment / user_x_group ) 往两头看, 会发现两头都是 1:n 关系. 也就是说, n:m 其实是由 2 个 1:n 合成的.
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
是不是感觉有点晕, 在这条华丽丽的分隔线之后, 其实, 我想说…… 忘了上面那些话吧!! 权当我没说过…
在项目实践中, 进行数据库设计, 按下面两步走可能还更快, 准, 狠:
(1) 跟着感觉走, 把项目中涉及到的数据按照它们的逻辑关系拆成一坨一坨的样子
(2) 分析第 (1) 步得到的那些坨坨, 它们之间有什么样的关系? 把这些关系用线连起来, 稍加思索, 应该在线的哪一端加外键(关联线另一端的主键), 加上即可.
20. 在服务器端与数据库交互
本小节我们将从数据库提取数据, 并将其返回前端. 友情提醒, 本小节玩的是服务器端代码( VS Code, Node.js ), 别跑错场了哦 ~
20.1 基础知识
先用一个简单的例子介绍一下在 Node.js 的世界如何与数据库交互…
首先, 我们需要安装一个 Node.js 的第三方库 ( mysql ), 用于连接 MySQL 数据库.
控制台项目根目录下执行:
1 | npm install mysql --save |
新建文件 dbTest.js, 代码如下
Code 20-1: dbTest.js
1 | const mysql = require('mysql'); // 引入mysql |
上述代码大致分为 4 段:
(1) 引入第三方库 ( mysql )
(2) 创建数据库连接对象
(3) 执行数据库操作 ( SQL语句 )
(4) 断开数据库连接. 使用完连接对象一定记得断开连接, 就像你打完电话要挂断一样, 否则数据库连接资源尽早会被你耗尽. ( 其它技术中也是如此, 切记, 切记 ! )
特别注意: 数据库查询的结果是通过回调函数的参数 (result) 返回的. ( 第 13 行 )
执行 dbTest.js, 测试一下呗 ~ 在控制台下执行:
1 | node dbTest.js |
如果一切顺利, 应该可以看到控制台输出了如下内容:
1 | [ |
以上这即是执行select * from user_info的查询结果 ( Code 20-1 第 17 行输出 )
注意, 查询结果是一个数组 ( 观察第1行和第34行 ), 查询结果中的每一行对应这里数组中的一个元素 ( 如: 第 2 ~ 9 行为查询结果集的第 1 行数据 )
可能你会觉得输出中的RowDataPacket有点诡异, 别在意, 当作没看见就行…. ( JavaScript 中数组元素是可以取名字的, 呵呵 )
Node.js 世界中的数据库交互就这么简单, 学会了吧~
如果想强行停止控制台中的程序可按 Ctrl + C
20.2 向小程序端返回数据库中的数据
本小节让我们来修改服务器端代码 ( index.js ), 从数据库查询数据并返回给小程序端.
先给代码吧 ~
Code 20-2: index.js
1 | const express = require('express'); // 引入Express |
有了 20.1 节的基础, 看上面这段代码应该问题不大… 仅提示几个小地方:
第 11 ~ 14 行, 先准备一个空对象(data), 以备存储将要向前端返回的查询结果. 第 17 行和第 32 行分别把两步查询的结果填充到 data 中, 最后在第 36 行向前端返回
conn.query() 无论查询得到的是多行数据或是一行数据, result 都是数组.
也就是说, 即使 26 行的 select 语句百分之百只会返回一行数据, result 也是一个数组, 大概这样子: result = [ { … } ]
所以, 第 27 行, 当我们需要取得 u1 用户的信息时, 应使用
result[0]
来吧 ~ 小程序端刷新一下试试… 哦嗬 ~ 小程序端界面又白茫茫一片了…
来~ 浏览器里打开 http://localhost:8000 试试 ~ 你将会看到浏览器中输出的是 {"userInfo":null,"diaries":[]}
见鬼啦! 开始怀疑人生了吧 ~
难道是没查到数据?
并非如此! 不信的话, 在第 27, 32 行之前插入console.log(result); 试试, 你会发现确实查询到了数据…
暂时别怀疑人生… 我们来调试一下, 分别在 27, 32, 39 行行号前单击(设置断点), 然后浏览器刷新一下…
是不是程序运行时会先后在 39 → 27 → 32 行暂停…
发现诡异之处了吗? 为什么不是 27 → 32 → 39 ?
回到 20.1节, 看一下有一个加粗了的”特别注意”, 又熟视无睹了吧…
行吧 ~ 再解释一下…
Node.js 中, 对于耗时较长的操作, 通常会以异步的方式进行, 执行结果将以回调方式返回, 避免耗时操作阻塞线程的执行.
不明白的话, 当我没说, 我们还是直接解释代码吧 ~
当我们调用conn.query(sql, function(err, result){ ... })时, 程序向数据库发出查询指令(sql)后将立刻接着向后执行, 并不等待数据返回. 而当 MySQL 将查询结果返回时才触发回调函数, 并将结果注入到参数 result 中.
所以, 第 39 行代码执行时, data 中都还没有数据 ( 因为查询结果还没返回 )
晕的话, 再回头看一遍吧 ~
好吧, 所以代码大概应该这样写…
Code 20-3: index.js
1 | const express = require('express'); // 引入Express |
注意第 26 ~ 39 行, 两步查询需要”嵌套”起来, 即: 先查用户表, 取得数据, 回调后再查日记表, 回调后最后才向前端返回数据.
OK ~ 现在再刷新小程序试试, 这回效果出来了吧 ~
21. 改进一下
经过前一小节的折磨, 不得不说, 异步回调真是很容易让人头脑发昏! 也会让代码变得越来越难写…
前一节我们仅只是分别执行两个查询, 已经可以看到两层嵌套的异步回调(Code 20-3, 第 26 ~ 39 行). 试想, 如果需要依次执行 n 个查询, 那非得搞出神经病…
其实, 这段代码已作了很大程度的简化, 非常不严谨, 比如: 出错时的异常处理都被省略了. 如果好好写, 代码量还会更大, 情况会更复杂.
如果想挑战一下的话, 可以设想: 如果第 27 行或第 31 行处的 err 不空时(即: 查询出错), 你应该怎么处理? 呵呵~ 我只是随口说说, 这事要做好不容易…
业界把上述这种情况称作回调陷阱或回调地狱.
回调陷阱/地狱并非 Node.js 的专利, 也并非 JavaScript 特有的东西, 只是在 Node.js 的世界, 为了追求所谓的”无阻塞高并发”, 回调函数被大量使用, 才会让所谓回调陷阱/地狱问题更加突显.
为了走得更远, 本节我们缓一缓, 整理一下代码…
21.1 使用 Promise
Promise 是什么? 怎么用? 这个说来话太长, 本文不打算详说…
这里, 我们直接使用, 至于怎么用, 有什么好处, 相信看完本节你会有一些心得.
修改上面 Code 20-3 的代码…
Code 21-1: index.js
1 | const express = require('express'); // 引入Express |
这里我们把原先 app.get(‘/‘, async function() { … }) 中的一部分代码(Code 20-3, 第 16 ~ 38 行) 提了出来, 封装成 3 个函数: getConnection, getUserInfoById 和 getAllDiaries, 解释一下…
第 8 ~ 16 行, 将获取数据库连接对象的代码封装为一个函数(getConnection), 以便重用(复用).
第 22 行, 注意到了没? 这里的
conn.query( ... )和我们此前使用的样子有一丢丢不一样.此前我们是这样用的:
conn.query(sql, callback), 参数 sql 是要执行的 SQL 语句, callback 则是回调函数而这里使用了 query 函数的另一种重载形式:
conn.query(sql, params, callback), 其中…- 参数 sql 还是要执行的 SQL 语句, 但不同的是这里的 sql 可带参数占位符 ( ? ), 执行前将自动使用具体的参数值替换
- params 即是具体参数值组成的数组. 注意 2 点: (1) 即使只有一个参数, 也必须封装为数组. (2) 有多个参数时, params 中参数值顺序应与 sql 中的占位符顺序一致.
第 19 ~ 31 行, 将查询用户信息的代码封装为 getUserInfoById 函数.
此函数返回一个
Promise对象. 非常不专业地解释一下 Promise …getUserInfoById 函数就像一个专门帮人查资料的小弟, 如果我们有需要就去找他. 首先, 我们会把查询条件(u1)给小弟, 小弟会给了你一个承诺(Promise), 大意是: 等着吧, 查到会通知你的. 然后你就回家了… 根据实际情况, 可能你会得到 2 个结果, 1: 查到的资料, 2: 出错了
呵呵, 故事有点突兀… 结合代码说一下… 如果查询出错, 小弟会以 reject 的方式通知你(24行, 同时将出错信息带回), 如果查询成功则以 resolve 的方式告诉你结果(26行). 在小弟干活的过程中, 你需要等待结果 ( 第 56 行, await )
特别注意:
- getUserInfoById() 函数返回的是 Promise 对象, 如果你想获得查询结果, 应在调用时使用 await关键词 ( 第 59 行 )
- 若函数体内现出await, 那么此函数必须添加关键字async ( 第 49 行 ), 表明此函数含异步过程
- 一个函数若加了 async 关键字, 那么此函数将返回 Promise 对象, 无论函数中是否有 return new Promise ( … )
第 34 ~ 46 行, 将查询日记信息的代码封装为 getAllDiaries 函数.
现在来看 57 ~ 69 行部分的代码, 是不是变得好理解多了~
同时, 我们还使用异常捕获机制 ( try … catch … ) 优雅地处理了可能发生的异常. 异常处理很重要, 别让你的程序在风雨中飘摇!
可以故意把第 22 或 37 行的 SQL 语句写错 ( 比如: 把 user_info 写作 xxx )… 试试会发生什么情况?
从 Promise 中取得结果, 也可使用 .then() 的语法, 例如, 第 59 行, 可写作:
getUserInfoById(‘u1’).then( function (result) {
data.userInfo = result;
});
但在这里如果这样改造, 那….. 意义何在呢? 呵呵 ~
实践中应避免拼接 SQL 语句, 例如:
function getUserInfoById(userId) {
….
return conn.query(‘select * from user_info where id = ‘ + userId, function(){ … });
…
}
这将带来 SQL 注入攻击风险… 使用 Code 21-1 中的做法可在一定程度上规避 SQL 注入攻击风险.
21.2 进一步封装
从在上节的代码中(Code 21-1)我们可以感觉到, 有些代码其实是通用的, 或者说是可以复用的, 比如: getConnection(){ … }, conn.query( … )
如果我们把这些代码代码抽离出来, 单独封装成一个模块(module), 这样不仅可以提高代码的复用性, 降低代码的耦合度, 同时还可让你的程序变得更有条理, 更好管理.
呵呵, 暂时不能理解的话, 先跟着往下做吧~ 回头再来理解上面这段话…
在项目根目录下创建 utils 文件夹, 并在其中新建文件 dbUtil.js. 这里, 我们打算把与数据库操作相关的代码封装到 dbUtil 模块中:
Code 21-2: /utils/dbUtil.js
1 | const mysql = require('mysql'); // 引入mysql |
注意第 29 ~ 31 行, 在 Node.js 的世界里每一个 .js 文件是天生就是一个独立的模块(module), 模块内的成员均是私有的, 即模块之外不可直接访问. 为了向”外界”暴露某个”私有成员”, 需要使用 module.exports.
小疑问
第 18 行的 conn.query() 是以异步回调的方式返回查询结果, 那么会不会出现查询结果还没返回, 代码就执行到第 25 行的 conn.end() 而关闭连接, 从而导致错误呢?
如果你有这样的疑问, 那么说明你对异步回调的游戏规则已经很熟悉了, 你的担心很有道理, 棒棒哒!
不过, 在 mysql 模块的文档提到, conn.end() 会等待当前正在执行的命令执行完后才真正关闭连接. 所以, 上述代码应该是没问题的…
科普知识
我们俗称的 JavaScript, 其”学名”应叫 ECMAScript, 简称 ES.
在2015年6月以前, 我们使用的是 ES5 版本(2009年发布). 在那个年代, JavaScript 只被当作浏览器中运行的”小脚本”, 跑龙套的角色, 呵呵~ 在 ES5 标准中并没有模块的概念.
在那个时代, JavaScript 代码通过类似
<script src='...'></script>的方式引入后, 全部混杂在一起, 基本上相当于把各个 .js 文件中的代码都复制 + 粘贴在一起, 这就很凶险了… 就像一群疯子在公海搞军事演习, 一不小心就擦枪走火… 命名冲突, 代码相互耦合等问题层出不穷.当然, 一些聪明的娃娃会使用函数/对象进行封装, 以隔离代码/变量. 但谁又能保证这世界上是没有几个二货…
随着时代的发展, JavaScript 逐渐从浏览器里的”小脚本”成长为使用广泛的编程语言, 模块化成为了大家梦寐以求的东西. 所谓模块化, 可简单理解为将代码封装成相对独立的单元(模块), 在模块内部你想翻天都行, 但模块之间的相互协作则需要遵循一套规范的语法. 这其实是软件工程”高内聚, 低耦合”思想的体现.
在 JavaScript 模块化探索的过程中, 出现过很多规范(标准/建议), 比如: CommonJS, AMD, CMD… 它们都算是民间标准, 因为…. ECMA 官方似乎睡着了, 标准严重滞后…
顺带提一句, AMD 和 CMD 规范中支持模块异步加载, 因此, 它们更多地被用于浏览器端. 而 CommonJS 更多地被用于服务器端.
在 Node.js 出生的年代, ECMA 还在睡… 所以, 它在万千佳丽中选择了 CommonJS 作为其模块化方案…
直到 2015年6月, ECMA 终于醒了, 发布了 ECMAScript 6, ES6 顺应时代潮流, 引入了模块化规范. 但不幸的是, 它走出了一条自己的路… 虽然, 所体现的”思想”与世上已经存在的模块化方案一致, 但在具体的语法上多少有些细微的差异. 所以, 目前在模块化标准这事上, 似乎又开始群魔乱舞了…
随着 Node.js 版本的更替, 它也想着向正规军(ES6)靠拢, 但时至今日, 在 Node.js v14.7.0 版本中, 对标准的 ECMAScript 模块规范的支持仍处于实验阶段.
OK ~ 现在, 自然也需要对 index.js 中的代码进行调整:
Code 21-3: index.js
1 | const express = require('express'); // 引入Express |
注意, 第 2 行别写漏了哦 ~ 可以看到, 现在 index.js 变得清爽了不少…
干脆一不做二不休, 把查询用户/日记数据的代码也模块化一下吧~
项目根目录下创建 service文件夹, 并在其中新建两个模块文件: user.js, diary.js, 代码如下:
Code 21-4: /service/user.js
1 | const dbUtil = require('../utils/dbUtil.js'); // 引入dbUtil模块 |
Code 21-5: /service/diary.js
1 | const dbUtil = require('../utils/dbUtil.js'); // 引入dbUtil模块 |
再次回到 index.js 修改一下:
**Code 21-6: index.js **
1 | const express = require('express'); // 引入Express |
嘿嘿 ~ 这回我们的主程序(index.js)变得好清爽! 这就是我们要的效果…
index.js作为程序的”主控”, 负责启动程序, 分发任务.
service/user.js 和 service/diary.js分别负责用户和日记相关的事情.
utils/dbUtil.js负责和更底层的数据库打交道.
如果把我们现在的项目比作一个公司的话, index.js 很像是前台接待客户的姑娘, service/user.js 和 service/diary.js 则是具体干活的小伙子. 而 utils/dbUtil.js 更像是一个快递小哥, 负责在数据库与公司之间搬运货物(数据), 他可算是一个非常初级的持久层封装.
画个图示意一下, 请细品其中体现的分层设计思想…
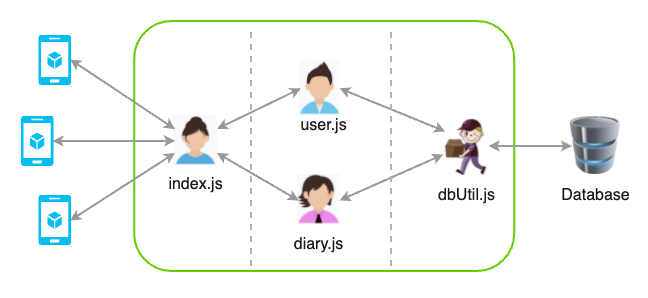
22. 数据库连接池
如果给目前完成的代码打分的话, 差不多可以得 3 朵小红花了…
观察 Code 21-2 ( /utils/dbUtil.js ) 的代码, 设想一个问题, 如果你的小程序大家都喜欢, 使用的人很多, 那么意味着数据库的交互将会很频繁.
每一次数据库交互都 建立连接 → 执行 SQL 命令 → 断开连接, 这对服务器的性能消耗会很严重, 同时效率也不高.
举个例子… 假设你家里住了很多亲戚, 你想打电话和他们聊两句… 你会和你爸说完, 立刻挂断电话, 然后再拨通电话, 和你妈说两句, 又立刻挂断电话, 然后再拨通, 和你七大姑聊吗? 如果真是这样, 中国移动会很 Happy ~
例子中, 拨通电话 = 建立连接, 聊两句 = 执行 SQL 命令, 挂断电话 = 断开连接.
显然, 生活中你的做法应该是: 拨通电话, 和你爸聊两句, 电话给你妈, 聊两句, 再把电话给你七大姑, 聊两句…. 最后挂断.
也就是说, 我们没有必要每次执行完 SQL 命令就把连接断开, 可以先把连接闲置, 需要再次执行 SQL 命令时直接使用已建立的连接发送命令, 这样效率就高多了.
当然, 对于数据库这种抢手货, 在很多人同时使用你的小程序时, 可能会在同一时刻有多条 SQL 命令需要执行, 因此可能需要同时建立多个连接.
小结一下… 为了提高效率, 我们很需要这样一个东西, 它能做到以下几点:
- 当我们需要数据库连接时, 只要伸手, 它就能提供给我们
- 当我们使用完连接后, 把连接交还给它, 它能管理好这些连接, 共享给其它人使用
- 如果连接需求量增大, 它能自动创建更多的连接, 以满足高峰期的需求
- 当连接需求量变小时(过了高峰期), 它能自动断开多余的连接, 但保持一个最低的连接持有量, 以便在需要时快速供应.
这里据说的 “它” 就是本节我们要使用的数据库连接池 ( Connection Pool )
通常数据库连接池会配置一个最小连接数(min) 和一个最大连接数(max), 在系统启动时, 连接池会预先建立 min 个连接, 需要时直接从连接池中取得连接, 使用完后归还连接池, 如果连接池有已没有空闲连接而又有新的连接需求, 则连接池会自动创建新的连接提供给需求方. 但连接池管理的总连接数不超过max, 若已到上限, 还有新的连接需求, 则需要排队等待. 当连接池中的空闲连接数超过 min 时, 会自动逐渐断开多余的连接.
嘿嘿 ~ 是不是很高级!
当然, 这里我不是要教你怎么做一个连接池, 我也没这个能耐, 我们用现成的就行… 但希望你能掌握方法, 因为, 无论你使用什么技术, 几乎所有和数据库打交道的场景都会使用到连接池, 它确实能很大程度地提高数据库交互效率.
OK ~ 来吧, 打开你的/utils/dbUtil.js文件, 把其中的代码改成下面的样子…
Code 22-1: /utils/dbUtil.js
1 | const mysql = require('mysql'); // 引入mysql |
保存一下, 其它地方的代码不用修改, 重启程序试试, 一切正常… 呵呵, 就这么简单 ~
- 第 4 行, 程序启动时直接使用
mysql.createPool ()创建连接池(pool), 参数与此前的 mysql.createConnection() 一样 - 第 15 行,
pool.getConnection()从连接池中获取数据库连接对象. 注意连接对象是以异步回调的方式返回. - 第 26 行, 用完连接后调用连接对象的
release()方法释放连接(归还给连接池)
其实, 上面的代码还可以再简化一下…
Code 22-2: /utils/dbUtil.js
1 | const mysql = require('mysql'); // 引入mysql |
第 15 行的 pool.query() 相当于 pool.getConnection → connection.query → connection.release
按理说, 在最后服务器关闭时还应该优雅地关闭连接池: pool.end() . 为免引起极度不适, 本文就不再扯了, 不优雅就不优雅吧 ~
话又说回来, 其实要优雅地关闭连接池也不难, 呵呵~ 可以参看这个: 健康检查和优雅地关闭 express, 自己搞一下.
关于 msyql 模块的官方文档, 有空读一读…
本文示例中未对 mysql 模块连接池的最大连接数进行配置, 使用默认值: 10. 至于最小活跃连接数, 我翻了官方文档, 似乎找不到, 可能是 0 吧 ~ 如果纠结, 自己翻翻文档.
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
到目前为止的代码: daily-reading_part5.zip
Revised on 2021/10/25 17:08:50 by Bailey
-
Next Post实例教程 - 微信小程序 (六)
-
Previous Post实例教程 - 微信小程序 (四)